I spent a day finishing the MVP for ResumeXP.
I finally have the full flow working from uploading a resume, to parsing the text, to sending it through the AI pipeline and then visualizing the results in a clean UI.
Once I started working on it, I could not stop until it was done. It felt exhilarating to see everything come together.
The upload and parsing flow was pretty straightforward.
Users can drop in a PDF, DOCX or TXT file and the analysis service would handle it.
What I used for each file type:
- ❖'react-pdftotext' library for PDF files, which takes the file object directly and returns the extracted text
- ❖'mammoth' library for DOCX files, by converting the file into to an ArrayBuffer, pass it to Mammoth itself, and grab the value field from the result
- ❖TXT files or other plain texts, you can just call file.text() which is convenient
Why did I parse the files on the client instead of the server?
I chose client side parsing because the text extraction requirements were straightforward and supported by lightweight browser libraries like above.
Parsing on the client reduced backend complexity and made the upload experience feel more responsive.
If the parsing logic became more complex or needed stricter validation, the server is always there.
Once the text is parsed and ready, it's sent to the AI pipeline.
This part was straightforward, and having some experience from RamAI doing something similiar helped a lot.
I built a dedicated API route that handles the entire process of:
- ❖Validating the input
- ❖Constructing a strict system prompt
- ❖Sending the request to the AI model
- ❖Cleaning up the AI's response
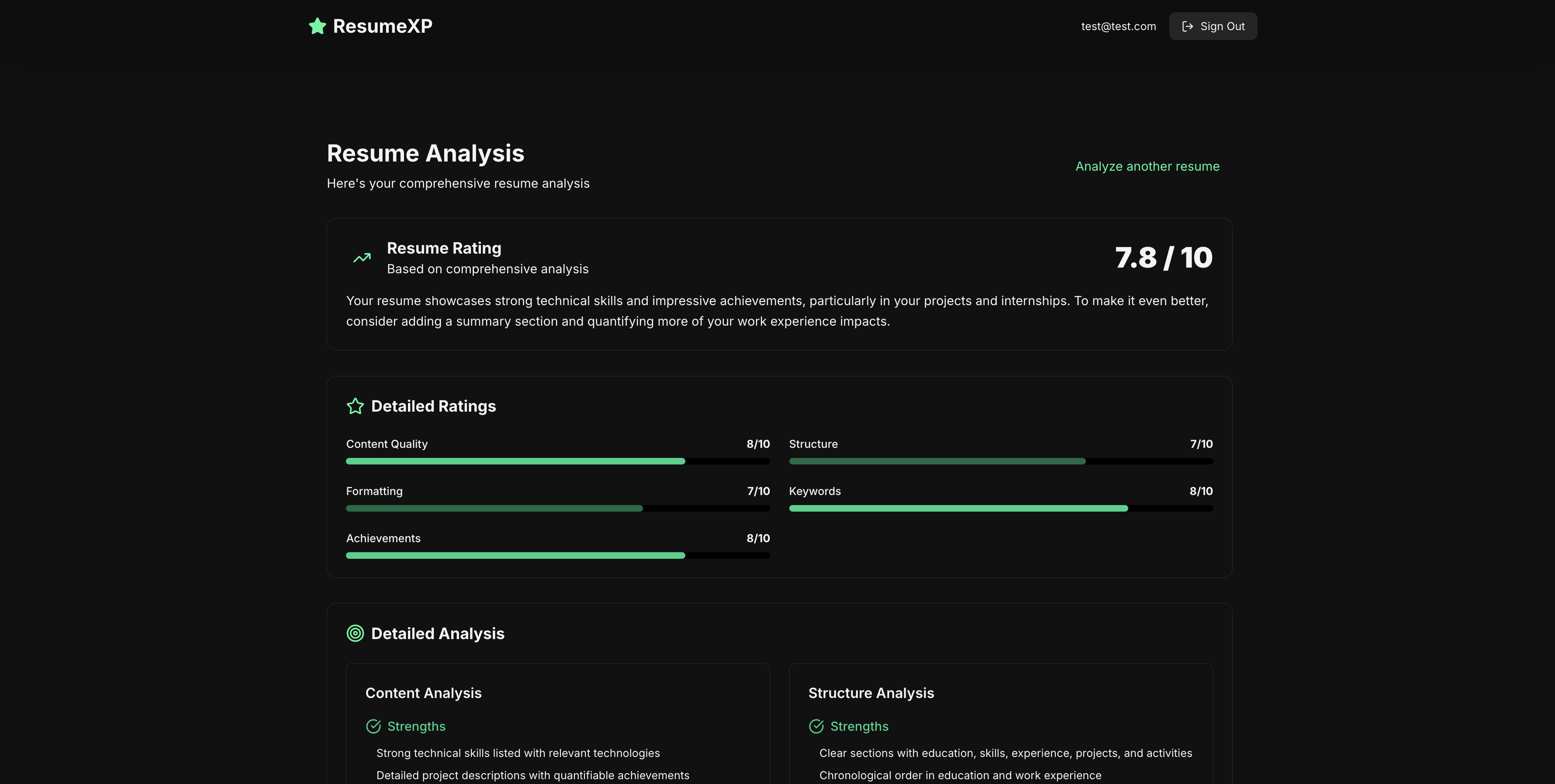
I designed the analysis pipeline so the AI is constrained to return a strictly defined JSON structure.
Returning unstructured text would make it difficult to reliably render results on the frontend, so a structured response was necessary.
By enforcing a schema, the frontend can confidently parse and visualize sections like ratings, strengths, weaknesses, and suggestions without hesitation.
To make this robust, I added a JSON extraction and validation step.
If the model includes extra text outside the expected structure, the parser strips it out and keeps only the valid JSON.
I also added defensive error handling for missing or malformed fields, ensuring the UI never renders partial or inconsistent data.
On the frontend, this structured output made it straightforward to design a clean, readable interface that visualizes the analysis clearly.
With the MVP complete, the focus now shifts to refining prompt quality, tightening formatting, and improving ATS checks to make the overall experience more polished.
7.8 out of 10? Guess I know what I'm fixing next.. :p